122 lines
3.7 KiB
Markdown
122 lines
3.7 KiB
Markdown
## 题目地址(820. 单词的压缩编码)
|
||
|
||
https://leetcode-cn.com/problems/walking-robot-simulation/submissions/
|
||
|
||
## 题目描述
|
||
|
||
```
|
||
给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A。
|
||
|
||
例如,如果这个列表是 ["time", "me", "bell"],我们就可以将其表示为 S = "time#bell#" 和 indexes = [0, 2, 5]。
|
||
|
||
对于每一个索引,我们可以通过从字符串 S 中索引的位置开始读取字符串,直到 "#" 结束,来恢复我们之前的单词列表。
|
||
|
||
那么成功对给定单词列表进行编码的最小字符串长度是多少呢?
|
||
|
||
|
||
|
||
示例:
|
||
|
||
输入: words = ["time", "me", "bell"]
|
||
输出: 10
|
||
说明: S = "time#bell#" , indexes = [0, 2, 5] 。
|
||
|
||
|
||
提示:
|
||
|
||
1 <= words.length <= 2000
|
||
1 <= words[i].length <= 7
|
||
每个单词都是小写字母 。
|
||
|
||
```
|
||
|
||
|
||
## 思路
|
||
|
||
读完题目之后就发现这题是一个后缀树。 因此符合直觉的想法是使用前缀树 + 倒序插入的形式来模拟后缀树。
|
||
|
||
|
||
下面的代码看起来复杂,但是很多题目我都是用这个模板,稍微调整下细节就能AC。我这里总结了一套[前缀树专题](https://github.com/azl397985856/leetcode/blob/master/thinkings/trie.md)
|
||
|
||

|
||
|
||
前缀树的 api 主要有以下几个:
|
||
|
||
- `insert(word)`: 插入一个单词
|
||
- `search(word)`:查找一个单词是否存在
|
||
- `startWith(word)`: 查找是否存在以 word 为前缀的单词
|
||
|
||
其中 startWith 是前缀树最核心的用法,其名称前缀树就从这里而来。大家可以先拿 208 题开始,熟悉一下前缀树,然后再尝试别的题目。
|
||
|
||
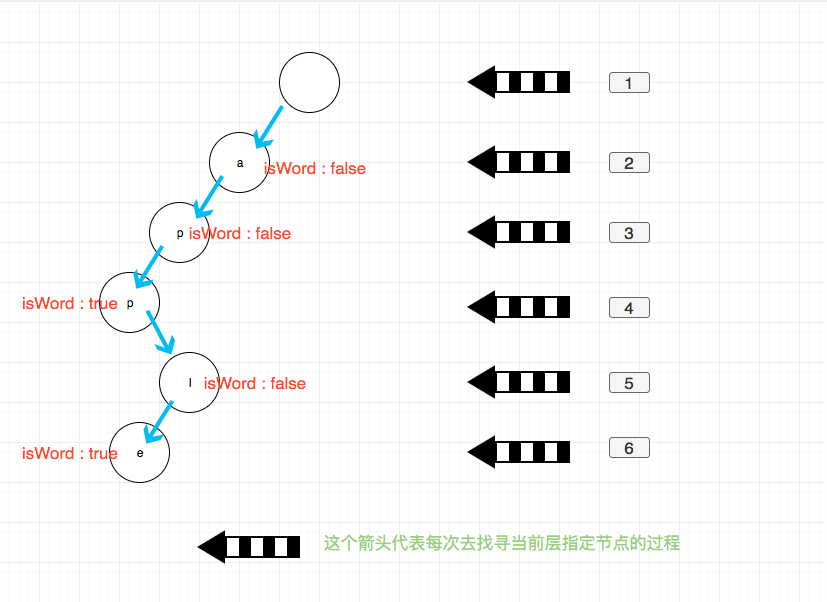
一个前缀树大概是这个样子:
|
||
|
||
|
||
|
||
|
||
如图每一个节点存储一个字符,然后外加一个控制信息表示是否是单词结尾,实际使用过程可能会有细微差别,不过变化不大。
|
||
|
||
|
||
这道题需要考虑edge case, 比如这个列表是 ["time", "time", "me", "bell"] 这种包含重复元素的情况,这里我使用hashset来去重。
|
||
|
||
## 关键点
|
||
|
||
- 前缀树
|
||
- 去重
|
||
|
||
## 代码
|
||
|
||
```python
|
||
class Trie:
|
||
|
||
def __init__(self):
|
||
"""
|
||
Initialize your data structure here.
|
||
"""
|
||
self.Trie = {}
|
||
|
||
def insert(self, word):
|
||
"""
|
||
Inserts a word into the trie.
|
||
:type word: str
|
||
:rtype: void
|
||
"""
|
||
curr = self.Trie
|
||
for w in word:
|
||
if w not in curr:
|
||
curr[w] = {}
|
||
curr = curr[w]
|
||
curr['#'] = 1
|
||
|
||
def isTail(self, word):
|
||
"""
|
||
Returns if the word is in the trie.
|
||
:type word: str
|
||
:rtype: bool
|
||
"""
|
||
curr = self.Trie
|
||
for w in word:
|
||
curr = curr[w]
|
||
return len(curr) == 1
|
||
class Solution:
|
||
def minimumLengthEncoding(self, words: List[str]) -> int:
|
||
trie = Trie()
|
||
cnt = 0
|
||
words = set(words)
|
||
for word in words:
|
||
trie.insert(word[::-1])
|
||
for word in words:
|
||
if trie.isTail(word[::-1]):
|
||
cnt += len(word) + 1
|
||
return cnt
|
||
|
||
```
|
||
|
||
***复杂度分析***
|
||
- 时间复杂度:$O(N)$,其中N为单词长度列表中的总字符数,比如["time", "me"],就是 4 + 2 = 6。
|
||
- 空间复杂度:$O(N)$,其中N为单词长度列表中的总字符数,比如["time", "me"],就是 4 + 2 = 6。
|
||
|
||
大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的LeetCode题解
|
||
|
||

|
||
|